This article is not for Pythonisms (like ContextManager), etc, the way things should normally be done in Python, but the more non-obvious way to solve problems or new features that are available specifically in Python.
Use / and * argument as separator for different forms of parameter entries!
There is special syntax to separate positional-only, positional/keyword, and keyword-only parameters.
Make a variant of existing class/object
This ninja technique is useful when you want to keep the object mostly the way it is but add/override a few things you think it didn’t do right without inheriting or use composition (hide a copy of object as a member) and write a proxy mirror for every member of it.
In C++, this situation is often used when you want to modify a concrete class that doesn’t have a virtual destructor, most notoriously STL which you are not supposed to inherit from (or else the client might pass a pointer to the parent/base so the child object’s destructors are not called as there are no vtables to keep track of which method to dispatch). In C++, this is often the few use cases that calls for private inheritance.
In Python, because everything is a recursive dict that specially named (magic) functions are recognized, there is a __getattr__ method that gets called whenever a member is accessed, which is the case when the member is called (in Python you simply get the functor as an attribute, aka value in the key-value pairs, in the dictionary and add brackets to call it). This means you can re-route what attributes (members) are returned simply by overloading __getattr__!
If you can overload __getattr__, it also mean you can redefine the member interface of your entire class! So a strategy to make a class have the same exact interface as another class is to hide a copy/reference to the underlying class and re-route the __getattr__ to the underlying object’s __getattr__! Here’s the gist of it:
This can be improved a little bit. Just pick a member name that won’t clash with the underlying object’s attributes/members and simply return the ‘hidden’ object when specifically requested, not self.__obj.__obj.
MATLAB’s classes are hard-wired to your class definition .m file, not something you can update on the fly as you please. Any attempts to do so (aka breaking the safeguards) are Undocumented MATLAB territory where you mess with the Java under the hood and change the metadata property to fool the objects to do what you want.
Python’s import structure is confusing. Learning by examples (i.e. imitating example code) does not help understanding the logic of it, and there are a lot of possible invalid combinations that are dead ends. One needs to understand the concepts below to use it confidently!
Just like C++ quirks, very often there’s valid reasoning behind this confusing Python design choice and it’s not immediately obvious. Each language cater certain set of use cases at the expense of making other scenarios miserable. That’s why there’s no best universal language for all projects. Know the trade-offs of the languages so you can pick the right tool for the job.
MATLAB’s one file per function/script design
MATLAB made the choice of having one file describe one exposed object/function/class/script so it maps directly into the mental model of file systems. This is good for both user’s sanity and have behavioral advantages for MATLAB’s interpreter:
Users can reason the same same way as they do with files, which is less mental gymnastics
Users can keep track of what’s available to them simply by browsing the directory tree and filenames because file names are function names, which should be sensibly chosen.
MATLAB leverages the file system for indexing available functions and defer loading the contents to the memory until it’s called at runtime, which means changes are reflected automatically.
Package/modules namespace models in MATLAB vs Python
MATLAB traditionally dumps all free functions (.m files) available in its search paths into the root workspace. Users are responsible for not picking colliding names. Classes, namespaces and packages are after-thoughts in MATLAB while the OOP dogma is the central theme of Python, so obviously such practices are frowned upon.
RANT: OOP is basically a worldview formed by adding artificial man-made constructs (meanings such as agents, hierarchy, relationships) to the idea of bundling code (programs) and data (variables) in isolated packages controlled (scoped) by namespaces (which is just the lexer in your compiler enforcing man-made rules). The idea of code and data being the same thing came from Von Neumann Architecture: your hard drive or RAM doesn’t care what the bits stands for; it’s up to your processor and OS to exercise self-restraint. People are often tempted to follow rules too rigidly or not take them seriously when what really matters is understanding where the rules came from, why they are useful in certain contexts and under what situations they do not apply.
Packages namespaces are pretty much the skeleton of classes so the structure and syntax is the same for both. From my memory, it was at around 2015 that MATLAB started actively encouraging users (and their own internal development) to move away from the flat root workspace model and use packages to tuck away function names that are not immediately relevant to their interests and summon them through import syntax as needed. This practice is mandatory (enforced) in Python!
However are a few subtle differences between the two in terms of the package/module systems:
MATLAB does not have from statement because import do not have the option to expose the (nested tree of) package name to the workspace. It always dumps the leaf-node to the current workspace, the same way as from ... import syntax is used in Python.
MATLAB does not have an optional as statement for you to give an alternative name to the package you just imported. In my opinion, Python has to provide the as statement as an option to shorten package/module names because it was too aggressively tucking away commonly used packages (such as numpy) that forcing people to spell the informative names in full is going to be an outcry.
Unlike free functions (.m files), MATLAB classes are cached once the object is instantiated until clear classes or the like that gets rid of all instances in the workspace. Python’s module has the same behavior, which you need to unload with del (which is like MATLAB’s clear).
Python’s modules are not classes, though most of the time they behave like MATLAB’s static classes. Because modules lacks instantiated instances, you can reload Python modules with importlib.reload(). On the other hand, since MATLAB packages merely manages when the .m files can get into the current scope (with import command), the file system still indexes the available function list. Changes in .m file functions reflects immediately on the next call in MATLAB as MATLAB detects file changes, yet Python has to reload the module to update the function names index because the only way to look at what functions are changed is revisiting the contents of an updated .py file!
MATLAB abstracts folder names (that starts with + symbol) as packages and functions as .m files while Python abstracts the .py file as a module (like MATLAB’s package) and the objects are the contents inside it. Therefore Python packages is analogous to the outer level of a double-packed (nested) MATLAB package. I’ll explain this in detail in the next sections.
Files AND directories are treated the same way in module hierarchy!
This comes with a few implications
if you name your project /myproj/myproj.py with a function def myproj(), which is a very usual thing most MATLAB users would do, your module is called myproj.myproj and if you just import myproj, you will call your function as myproj.myproj.myproj()!
you can confuse Python module loader if you have a subfolder named the same as a .py file at the same level. The subfolder will prevail and the .py file with the same name is shadowed!
The reason is that Python allows users to mix scripts, functions, classes in the same file and they classes or functions do not need to match the filenames in order for Python to find it, therefore the filename itself serves as the label for the collection (module) of functions, classes and other (script) objects inside! The directory is a collection of these files which itself is a collection, so it’s a two level nest because a directory containing a .py file is a collection of collection!
On the other hand, in MATLAB, it’s one .m file per (publicly exposed) function, classes or scripts, so the system registers and calls them by the filename, not really by how you named it inside. If you have a typo in your function name that doesn’t match your filename, your filename will prevail if there’s only one function there. Helper functions not matching the filename will not be exposed and it will have a static/file-local scope.
Packages in MATLAB are done in folders that starts with a + symbol. Packages by default are not exposed to global namespaces in your MATLAB’s paths. They work like Python’s module so you also get them into your current workspace with import. This means it’s not possible to define a module within a file like Python. Each filename exclusively represent one accessible function or classes in the package (no script variables though).
A module (in Python) is basically treating a file as a package folder, which contradicts with MATLAB’s function loading system’s design. So there’s only the concept of packages in MATLAB and no concept of modules in MATLAB. Multiple functions in a Python module should be written into one file per function in MATLAB and loaded as a package.
Python separated the two concepts (modules and packages) because .py file allows a mixture of scripts, classes and loose functions formed a logical unit with the same structure as packages itself, so they need another name called module to separate folder-based collection (logical unit) and file-based collections (logical unit).
This is very counterintuitive at the surface (because it defeats the point of directories) if you don’t know Python allowing user to mix scripts, functions and classes in a file meant the file itself is a module/collection of executable contents.
from (package/module) import (package/module or objectS) <as (namespace)>
This syntax is super confusing, especially before we understand that
packages has to be folders (folder form of modules)
modules can be .py files as well as packages
packages/modules are technically objects
The hierarchy for the from import as syntax looks like this:
package_folder > file.py > (obj1, obj2, ... )
This has the following implications:
from strips the specified namespace so importdumps the node contents to root workspace
import without fromexposes the entire hierarchy to the root workspace.
functions, classes and variables in the scripts are ALL OBJECTS.
if you do import mymodule, a function f in mymodule.py can only be accessed through mymodule.f(), if you want to just call f() at the workspace, do from mymodule import f
These properties also shapes the rules for where wildcards are used in the statement:
from cannot have wildcards because they are either a folder (package) or a file (module)
import is the only place that can have wildcards * because it is only possible to load multiple objects from one .py file.
import * cannot be used without from statement because you need to at some point load a .py file
it’s a dead end to do from package import * beacuse it’s trying to load multiple raw .py files to the root workspace instead of importing multiple objects defined in the .py file.
it also does not make sense (nor possible) to follow import * with as statement because there is no mechanism to map multiple objects into one object name
So the bottom line is that your from import as statement has to somehow load a .py file in order to be valid. You can only choose between these two usage:
load the .py file with from statement and pick the objects at import, or
skip the from statement and import the .py file, not getting to choose the objects inside it.
as statement can only work if you have only one item specified in import, whether it’s the .py file or the objects inside it. Also, if you understand the rationales above, you’ll see that these two are equivalent:
from package_A import module_file_B as namespace_C
import package_A.module_file_B as namespace_C
because with as statement, whatever node you have selected is accessed through the output namespace you have specified, so whether you choose to strip the path name structure in the extracted output (i.e. use from statement) is irrelevant since you are not using the package and module names in the root namespace anymore.
The behavior of from import as is very similar to the choices you have to make extracting a zip file with nested folder structures, except that you have to make a mental substitution that a .py file is analogous to a subfolder while the objects described in the .py file is analogous to files in the said subfolder. Aargh!
* Shallow assignment (transferring reference only) means the LHS does not have its own copy, so modifying the new reference will modify the underlying data on the RHS.
| Format-List -Property * or Format-List -InputObject
properties() methods() get()
List members (method and properties)’s prototypes
| Get-Member
Powershell specific
The UNCAPTURED output value in the last line of the block is the return value! Unary side effect statements such as $x++ do not have output value. Watch out for statements that looks like it’s going nowhere at the end of the code as these are not nop/bugs, but return value. This has the same stench as fall-throughs.
foreach() follows the last uncaptured output value return rule above doing a 1-to-1 map from the input collection to output collection (you can assign output to foreach() as it’s also seen as a function)
Powershell suck at binary operations between two arrays. Just an elementwise A+B you’d be thinking in terms of loops and worry about dimensions.
You can put if and loop blocks inside collections list construction, like this:
When used with classes and custom matrices/arrays, chaining fields/properties/methods by indices often do not work, when they do, they often give out only the first element instead of the entire array (IIRC, there are operator methods that needs to be coordinated in the classes involved to make sure they chain correctly). In short, just don’t chain unless in very simple, scalar cases. Always output it to a variable a access the leaf.
Negative (cyclic) indexing along with automatic descending range, along with the lack of ‘end’ keyword is a huge pain in the rear when you want to scan from left to right like A[5:end].
Instead, you’ll have to do $A[4..($A.length-1)] because the range 4..-1 inside A[4..-1] is unrolled as 4,3,2,1,0,-1 (thus scanning from right to left and wraps around) without first consulting with the array A like the end keyword in MATLAB does so it can substitute the ends of the range with the array information before it unrolls.
I am willing to bet that this behavior does not have a sound basis other than people thinking negative indices and descending ranges alone are two good ideas without realizing that nearly nobody freaking wants to scan from right to left and wrap around!
I had the same gripes about negative indices in Python not carefully coordinating with other combinations in common use cases which cases unintuitive behavior.
Range indexing syntax
# Powershell
1..10 # No step/skip for range creation
A[1..10] # No special treatment in array such as figuring out the 'end'
% MATLAB
A[start:(step):stop]
# Python
A[range(start,stop,step)]
# Slicing (it's not range)
A[(start):(stop):(step)] # Can skip everything
# In Python, A=X merely reassign the label A as the alias for X.
# Modifying the reassigned A through A=X will modify underlying contents of X
# To deep-copy contents without .Clone(), assign the full slice
A[:] = X
Hasthtable / Dictionaries
% MATLAB: Use dynamic fields in struct or containers.Map()
# Python: dictionaries such as {a:1, b='x'}
# Powershell: @{a=1, b='x'}
Structs
Powershell does not have direct struct or dynamic field name struct. Instead if your object is uniform (you expect the fields not to change much), use [PSCustomObject]@{}. You can also just use simple hashtable @{}, but for some reason it doesn’t work the way I expected when put into arrays when I try to reference it by array index.
Array rules surprises
Array comparisons are filtering operation (not boolean array output like MATLAB). (0..9) -ge 5 gives 5 to 9, not a list of False … False, True … True. To get a boolean array, use this shortcut:
(0..9) | % {$_ -ge 5}
Map-filter combo syntax is | ? instead of Map syntax | %
Powershell array (which are heterogenous data containers) are unpacked and stacked by default (in MATLAB, I had to write a lot of routines to unpack and stack cells of cells). To keep cells packed (in MATLAB lingo, it’s like ‘UniformOutput’, false in cellfun), add a comma unary operator in front of the operation that are expected to be unpacked like this:
.$_.Split('_')
Set Operations
This is one of the WTF moments of Powershell as a programming language. Convenient set operations is essential for most of the routine boring stuff that involves relational data. A lot of Powershell’s intended audience works in database like environment (like IT managers dealing with Active Directory), they have Group-Object for typical data analysis tasks, yet they make life miserable just to do basic set operations like intersection and differencing!
Powershell has a Compare-Object, but this is as unnatural and annoying to use as users are effectively rebuilding all 4 basic set-ops (intersection, union, set-diff, xor) based on any two! Not to mention you have to sift through table to get to the piece you wanted!
Basically Compare-Object out of the box
is a set-diff showing both directions (A\B and also B\A) at the same time. If you throw away the direction info, it’s xor.
if you want intersection, you’ll need to add -IncludeEqual -ExcludeDifferent
(WTF!) If you just specify -ExcludeDifferent, by definition there’s no output because by default Compare-Object shows you ONLY the two set-diffs and you are telling it to not show any diffs!
Union is specifying -IncludeEqual only. But it’d rather stack both then do a | Sort-Object - Unique
Some people might suggest doing | ? {$_ -eq $B} for intersection (or is-member). This is generally a bad idea if you have a lot of data because it’s in the O(n*n) runtime algorithm (loop-within-loop) while any properly done intersection algorithm will just sort then scan the adjacent item to check for duplicates, which gives O(n log(n)) time (typical sorting algorithm takes up most of the time).
If you noticed, it’s set operations within the outputs of Compare-Objects with the Venn diagram of -IncludeEqual -ExcludeDifferent switches! It’s doable, but totally unnecessary mindfuck that should not be repeated frequently.
In MATLAB land, I made my own overloading operators that do set operation over cellstr(), categorical and tabular objects (I went into their code and added the features and talked to TMW so they added the features later), sometimes getting into their sort and indexing logic as necessary. This shows how badly do I need set operations to come naturally.
One might not deal with it too much in low level languages like C++ (STL set doesn’t get used as much compared to other containers), but for a language made to get a lot of common things done (i.e. the language designer kind of reads the users mind), I’m surprised that the Powershell team overlooked the set operations!
Sets are very powerful abstractions that should not be made less descriptive (hard to read) by dancing around it with equivalent operations with some programming gymnastics! If these basic stuff are not built in, we are going to see a lot of people taking ugly shortcuts to avoid coding up these bread and butter functions and put it in libraries (or downloading 3rd-party libraries)!
Powershell surprises
Typical symbolic comparison operators do not work because ‘>’ can be misinterpreted as redirection in command prompts. Use switches like -gt (greater than) instead.
Redirection’s default text output uses UTF16-LE encoding (2 bytes per character). Programs assuming ASCII (1 byte per character) might not behave as intended (e.g. if you use copy command merge an ASCII/UTF8 file with UTF16-LE, you might end up with spaces in the sections that are formatted with UTF16-LE)
Cannot extract string matches from regex without executing a -match which returns boolean unless we use the the $matches$ spilled into variable space. Consider [regex]::Match($Text, $Pattern).Groups[1].Value
Methods are called with parenthesis yet functions are not called with parenthesis, just like cmd-lets! Trying to call a function with multiple input arguments with parenthesis like f(3,5) will be interpreted as calling f with ONE ARGUMENT containing an ARRAY of 3 and 5!
Write-Host takes everything after it literally (white spaces included, almost like echo command), with the exception of plugging in $variables! If you want anything interpreted, such as concatenation, you need to put the bracket around the whole statement!
Libraries and Modules
Reload module using Import-Module $moduleName -Force
For GUI development, we often start with controls (or widgets) that user interact with and it’ll emit/run the callback function we registered for the event when the event happens.
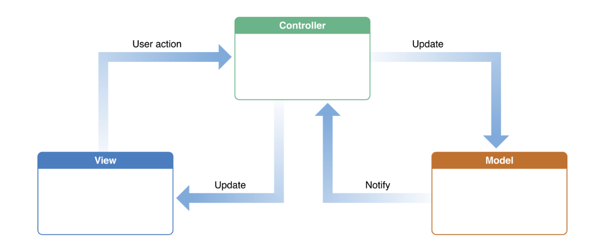
Most of the time we just want to read the state/properties of certain controls, process them, and update other controls to show the result. Model-View-Controller (MVC) puts strict boundaries between interaction, data processing and display.
The most common schematic for MVC is a circle showing the cycle of Controller->Model->View, but in practice, it’s the controller that’s the brains. The view can simultaneously accept user interactions, such as a editable text box or a list. The model usually don’t directly update the view directly on its own like the idealized diagram.
From https://www.educative.io/blog/mvc-tutorial
With MVC, basically we are concentrating the control’s callbacks to the controller object instead of just letting each control’s callback interact with the data store (model) and view in an unstructured way.
When learning Flutter, I was exposed to the Redux pattern (which came from React). Because the tutorials was designed around the language features of Dart, the documentation kind of obscured the essence of the idea (why do we want to do this) as it dwelt on the framework (structure can be refactored into a package). The docs talked a lot about boundaries but wasn’t clearly why they have to be meticulously observed, which I’ll get to later.
The core inspiration in Redux/BLoC is taking advantage of the concept of ‘listening to a data object for changes’ (instead of UI controls/widget events)!
Instead of having the UI control’s callback directly change other UI control’s state (e.g. for display), we design a state vector/dictionary/struct/class that holds contents (state variables) that we care. It doesn’t have to map 1-1 to input events or 1-1 to output display controls.
When an user interaction (input) event emitted a callback, the control’s callback do whatever it needs to produce the value(s) for the relevant state variable(s) and change the state vector. The changed state vector will trigger the listener that scans for what needs to be updated to reflect the new state and change the states of the appropriate view UI controls.
This way the input UI controls’ callbacks do not have to micromanage what output UI controls to update, so it can focus on the business logic that generates the content pool that will be picked up by the view UI controls to display the results. In Redux, you are free to design your state variables to match more closely to the input data from UI controls or output/view controls’ state. I personally prefer a state vector design that is closer to the output view than input controls.
The intuition above is not the complete/exact Redux, especially with Dart/Flutter/React. We also have to to keep the state in ONE place and make the order of state changes (thus behavior) predictable!
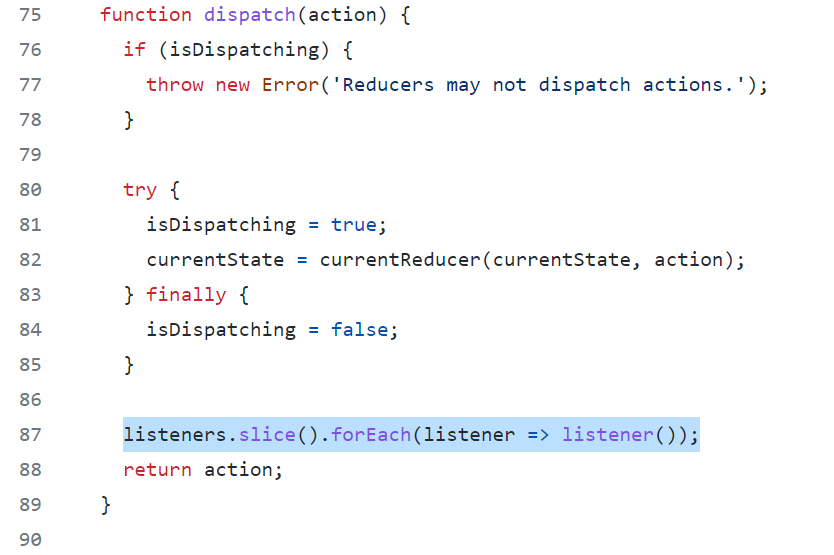
Actions and reducers are separate. Every input control fires a event (action signal) and we’ll wait until the reducers (registered to the actions) to pick it up during dispatch() instead of jumping on it. This way there’s only ONE place that can change states. Leave all the side effects in the control callback where you generate the action. No side effects (like changing other controls) allowed in reducers!
Reducers do not update the state in place (it’s read only). Always generate a new state vector to replace the old one (for performance, we’ll replace the state vector if we verified the contents actually changed). This will make timing predictable (you are stepping through state changes one by one)
In Javascript, there isn’t really a listener actively listening state variable changes. Dispatch (which will be called every time the user interacts using control) just runs through all the listeners registered at the very end after it has dispatched all the reducers. In MATLAB, you can optionally set the state vector to be Observable and attach the change listener callback instead of explicitly calling it within dispatch.
Here is an example of a MATLAB class that captures the spirit of Redux. I added a 2 second delay to emulate long operations and used enableDisableFig() to avoid dealing with queuing user interactions while it’s going through a long operation.
classdef ReduxStoreDemo < handle
% Should be made private later
properties (SetAccess = private, SetObservable)
state % {count}
end
methods (Static)
% Made static so reducer cannot call dispatch and indirectly do
% side effect or create loops
function state = reducer(state, action)
% Can use str2fun(action) here or use a function map
switch action
case 'increment'
fprintf('Wait 2 secs before incrementing\n');
pause(2)
state.count = state.count + 1;
fprintf('Incremented\n');
end
end
end
% We keep all the side-effect generating operations (such as
% temporarily changing states in the GUI) in dispatch() so
% there's only ONE PLACE where state can change
methods
function dispatch(obj, action, src, evt)
% Disable all figures during an interaction
figures = findobj(groot, 'type', 'figure');
old_fig_states = arrayfun(@(f) enableDisableFig(f, 'off'), figures);
src.String = 'Wait ...';
new_state = ReduxStoreDemo.reducer(obj.state, action);
% Don't waste cycles updating nops
if( ~isequal(new_state, obj.state) )
% MATLAB already have listeners attached.
% So no need to scan listeners like React Redux
obj.state = new_state;
end
% Re-enable figure obj.controls after it's done
arrayfun(@(f, os) enableDisableFig(f, os), figures, old_fig_states);
src.String = 'Increment';
end
end
methods
function obj = ReduxStoreDemo()
figure();
obj.state.count = 0;
h_1x = uicontrol('style', 'text', 'String', '1x Box', ...
'Units', 'Normalized', ...
'Position', [0.1 0.3, 0.2, 0.1], ...
'HorizontalAlignment', 'left');
addlistener(obj, 'state', ...
'PostSet', @(varargin) obj.update_count_1x( h_1x , varargin{:}));
uicontrol('style', 'pushbutton', 'String', 'Increment', ...
'Units', 'Normalized', ...
'Position', [0.1 0.1, 0.15, 0.1], ...
'Callback', @(varargin) obj.dispatch('increment', varargin{:}));
% Force trigger the listeners to reflect the initial state
obj.state = obj.state;
end
end
%% These are 'renders' registered when the uiobj.controls are created
% Should stick to reading off the state. Do not call dispatch here
% (just leave it for the next action to pick up the consequentials)
methods
% The (src, event) is useless for listeners because it's not the
% uicontrol handle but the state property's metainfo (access modifiers, etc)
function update_count_1x(obj, hObj, varargin)
hObj.String = num2str(obj.state.count);
end
end
end
Since MATLAB R2015b, there’s a new feature called repelem(V, dim1, dim2, ...) which repeats each element by dimX times over dimension X. If N (dim1) is scalar, each V is uniformly repeated by N times. If N is a vector, it has to be the same length as V and each element of N says how many times the corresponding element in V is repeated.
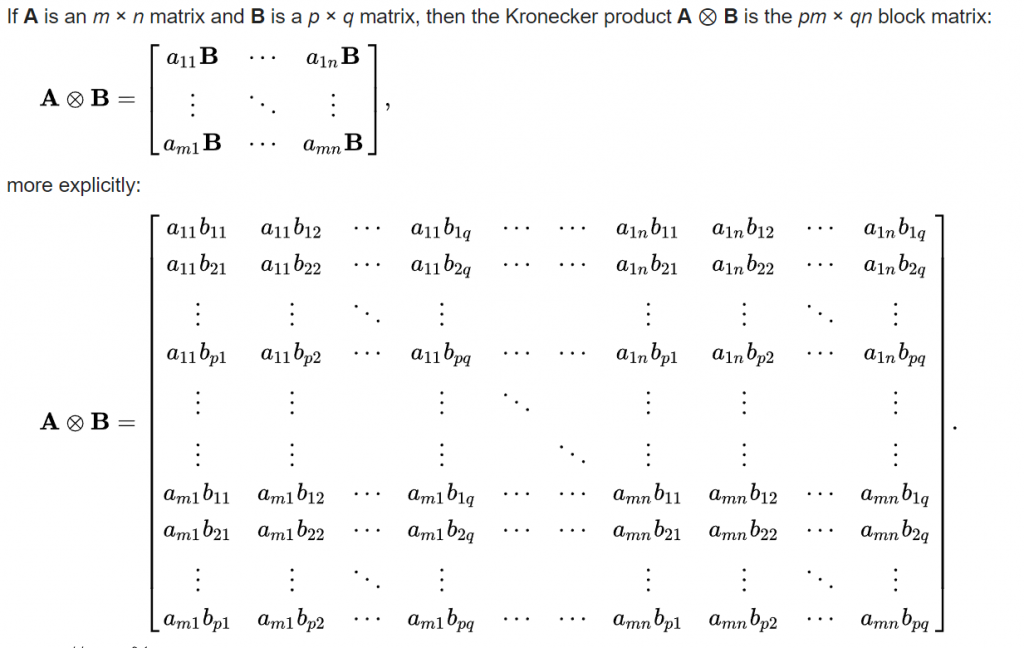
The scalar case (repeat uniformly) can be emulated by a Kronecker product multiplying everything with 1 (self):
kron(V, ones(N,1))
Just replace all the elements b with 1 so we are left with elements of A repeating the way we wanted
Kron method is conceptually smart but it has unnecessary arithmetic (multiply by 1). Nonetheless this method is reasonably fast until TMW finally developed a built-in function for it that outperforms all the tricks people have accumulated over decades.
The vector case (each element is repeated a different number of times according to vector N) is basically decoding Run-Length Encoding (RLE), aka counts to placements, which you can download maturely written programs on MATLAB File Exchange (FEX). There are a bunch of cumsum/diff/accumarray/reshape tricks but at the end of the day, they are RLE decoding in vectorized forms.