Function signature system, which allows users to use the same function name in different functions as long as they differ in the combination of
input arguments types
const modifiers counts as a different input argument type
object const-ness (whether it’s const-method or not) – this only make sense with classes
and C++ will figure out what to call by matching the call with the available combinations (signatures).
C does not allow the same function name to be used in different places, so under the hood, it’s done through name mangling (generating a unique ‘under-the-hood’ function name based on the signature). This mechanism has a lot of implications that a professional programmer should observe:
since C does not mangle its names in the object code, they’ll need to be wrapped around with extern “C” block in a C++ program so C++ won’t pervert (mangle) their function names with input arguments.
[24] parameter defaulting might be ambiguous with another function that does not have the said parameter (the compiler will cry about it)
[26] access controls/levels must play no part in resolving signatures because access level must not change the meaning of a program!
C++ resolve function overloading using signatures within its local namespace. Function overloading works for both
free functions (free functions are at the root namespace), as well as
classes (the name of the class itself is the namespace)
In structured programming (like C and C++), the building abstractions is program (functions) and data (variables).
Under the hood, especially in von-Neumann architecture’s perspective, functions and variables are both just data (a stream of numbers) that can be moved and manipulated the same way just like data. It’s all up to how the program designer and the hardware choose to give meaning to the bit stream.
Namespaces
In C, we can only scope our variables 3 ways: global, static (stays within same file/translation unit) and local. Sharing variables across functions in different translation units can only be done through
globals (pollutes namespace and it’s difficult to keep track of who is doing what to the variables and the state at any time)
passing (the more solid way that gives tighter control and clearer data flow, but managing how to pass many variables in many places is messy, even with struct syntax)
Bundling program with data gives a new way to tightly control the scope of variables: you can specify a group functions allowed to share the same set of variables in the bundle WITHOUT PASSING arguments.
The toolchain modified to recognize the user-defined scope boundaries which bundles program and data into packages, thus reducing root namespace pollution. The is implemented as namespace keyword in C++
Organizing with namespaces is basically justifying the mentality of using globals (in place of passing variables around intended functions) except it’s in a more controlled manner to keep the damages at bay. The same nasty things with gloabls can still appear if we didn’t design the namespace boundaries tightly so certain functions have access to variables that’s not intended for it.
Therefore, namespaces works nearly identical to a super-simple purely static class (see below) except you lose inheritance and access modifiers in classes in exchange for allowing anonymous namespaces.
Classes extends the idea of namespaces by allowing objects (each assigned their own storage space for the variables following the same variable layout) to be instantiated, so they behave like POD (Plain Old Data) in C. We should observe that when overloading operators
[15] allow (a=b)=c chaining by returning *this for operator=
[21] disallow rvalue assignment (a+b)=c by returning const object
In the most primitive form (no dynamic binding and types, aka virtuals and RTTI), function (method) info is not stored within instantiated objects as the compiler will sort out what classes/namespace they belong to. So it screams struct in C!
C struct is what makes (instantiates) objects from classes!
Note that C structs do not allow ‘static fields’ because static members is solely a construct of namespaces idea in C++! C++ has chosen to expand structs to be synonymous to classes that defaults to private access (if not specified) so code written as C structs behaves as expected in C++.
Technically there’s no static class in C, but a class with all members and functions declared static.
Static classes are like namespaces in many ways. Because no object is constructed (it’s just holding a bunch of variables and functions in the free space), a lot of features and syntax with regular classes do not make sense with static classes.
Because no objects are instantiated
No constructors or destructors (no objects to make/destroy)
No operator overloading (you need an instantiation to pass arguments to operator methods)
No overriding because there are no objects for you to upcast (nor there’s an object to store the vtable from the virtual keyword)!
Static members and methods are treated as free variablesscoped by namespaces
Like C, static members variables live in .bss (not explicitly initialized ones will be zero-initialized) or .data (initialized) sections, not on stack/heap! Exception: static const int is internally seen as enum, which the compiler uses it to plug values in the code instead of allocating space for it.
Therefore the syntax is pretty much like free static/global variables
No constructor to build member variables within the class definition, so they must be defined OUTSIDE the class definition at the top level (just like static/globals), with a SRO (scope resolution operator).
Static methods acts like (and function overloads the same way as) free functions. That’s why we often use static methods for helpers.
Namespaces has no access modifiers (public/protected/private/friend), but in return only namespaces can be unnamed/anonymous (which behaves as private)!
Namespaces cannot be inherited, but static classes can!
Inherited members ARE REFERENCES to the parent! There’s no extra copies of underlying data if that member is successfully inherited (not shadowed)!
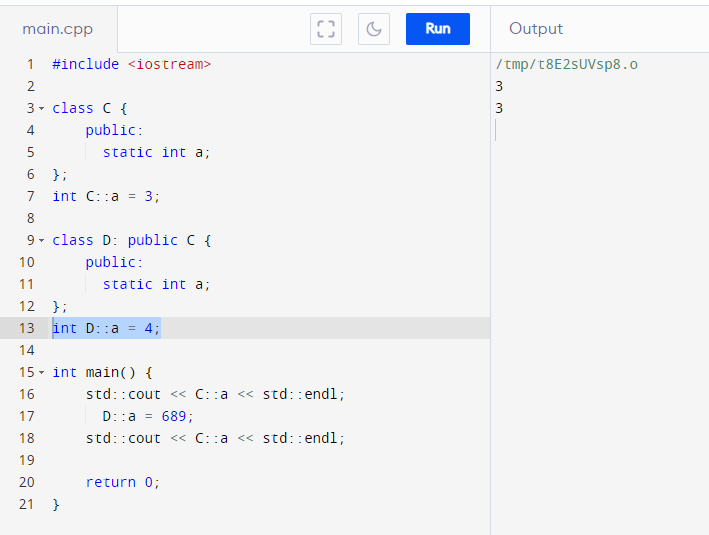
Members (function or variables) can only be shadowed in the child (never overridden since it’s not an object), which creates a NEW stack variable and hid the reference to the parent member
Static class’s inheritance behavior is the same across static classes object-bearing classes! It’s actually more explicit with static members as you’ll need two declarations outside the classes if you shadow.
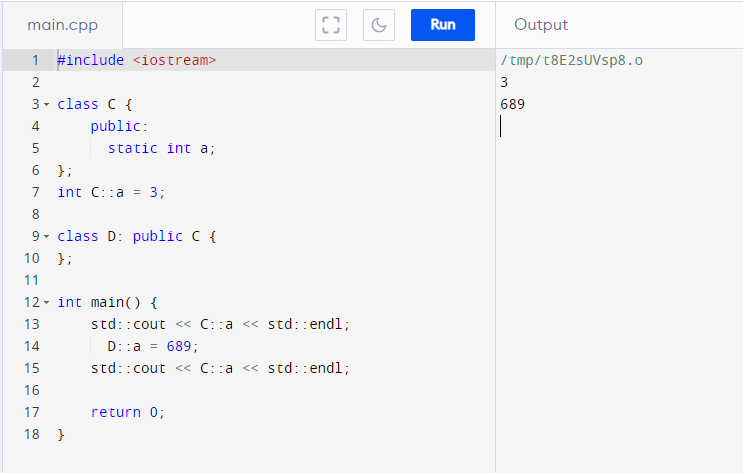
I am pointing this out to show that inheriting static classes IS NOT cloning namespaces! Static classes behaves as if it’s just ONE CHILD object created on the .bss/.data section (the section for static variables).
This means unlike object-bearing classes, the static class Parent cannot exist on its own if its children are defined!
C++ rules are almost always sensible and coherent; but when combined, sometimes the implications could be surprising on the first sight! When we try to extrapolate expected behaviors in C++, very often we have to think not in terms of the convenient syntax, but the implications of its ground rules (a lot of them stems from C)!
pointers are just integers to memory locations – [25] integer and pointers might be indistinguishable in signature resolution
code (CPU instructions) and addresses are treated the same way as a stream of data – concept of function pointers leads to lambda (functors) – classes came from structs containing data and function pointers (combined with namespaces)!
unchecked type declarations: the compiler trusts your interpretations of data – leads to run-time features such as overriding (virtual methods)
handles (pointers and references) has unrestricted power – [29] can const_cast it away if the handle is exposed (bad idea)
Performance-first design choice
do not pay performance penalty for features not used – static compilation and binding by default – unchecked type declarations (see above)
static compilation: the compiler tries to know everything at compile time
static binding by default (cheapest) – pay extra to use virtual methods (overriding) – [38] default parameter values are statically bound and not stored in vtable (i.e. overridden child method’s default values are ignored and parent’s default values are used ONLY WHEN called through up-casts)
inline is at the mercy of the optimizer (which can choose to emit an object if decided inlining is counter-productive). Mechanism that forces a function pointer to exist (pointing the function, virtual functions creates the pointer in vtable)
Toolchain
preprocessor (parser & macros)
compiler (create object files per translation unit, which is .c file in C) – access control (encapsulation) extends the old trick of emulating private in C++ through macros by marking functions as static (local within translation unit) in C.
linker (combine object files and adjust the addresses)
Templates behaves like a combination of macros (copy-and-paste with parameters) except it’s spread across the toolchain like inline optimizations:
Code bloat (one copy per type combination)
Can only live in the header files (it’s a template, not realized code, so no object is emitted like a .cpp file)
Parsing (language design)
most vexing parse [Effective STL Item 6]: if something can be interpreted as a function declaration, it will be interpreted as a function declaration
Plain Old Data Types (C++ classes tried to emulate in their operator overloading behavior)
[15] allow (a=b)=c chaining by returning *this for operator=
[21] disallow rvalue assignment (a+b)=c by returning const object
If you’ve programmed in (or studied) C++ long enough, like you have read Scott Meyers’s Effective C++, which is a book organized in, jokingly, commandments like ‘thou shall make destructors virtual’. There’s a lot of stuff to remember.
I’ve found an approach to make the ideas stick: by understanding the rationale behind these commandments through the lens of ‘What would you do if you were to make C++ (features) out of C?‘
C++ is not a language designed from scratch. A lot of quirks and oddities in C++ came straight from the philosophy and the language features naturally available in C. With the right jargons (concepts), you will find a lot of the seemingly counter-intuitive behavior ‘it ought to be like this because of (insert design choice here)‘.
This is what we are going to explore in the “Rational Behind C++ Commandments” (RBCC) blog post series which came from my notes when I was going through Scott Meyer’s book. Once you get the ideas, you should be able to come up with the rules in Effective C on your own (so you don’t have to blindly remember them).