I’ve been using CPIME for ages and I’m comfortable with Sidney Lau’s phonetic scheme. Jyutping is unnatural to Hongkongers because we do not consider ‘j’ a ‘y’ sound like Germans do.
However, since Windows 10, there aren’t much choices when it comes Cantonese IME that defaults to Sidney Lau’s and yet it accommodates common swearwords (including the most common ones that were technically incorrect) well. The only reasonable choice is Andrew Choi’s CAP, which I will write about how to get it working for Windows 10 on another blog post.
There aren’t much choices for Linux either. There’s RIME, but it’s super hard to install and Sidney Lau’s phonetic scheme is buried deep down that can only be changed with shortcut keys during the IME composition mode. The deal breaker is t.he lack of swearword support. Being able to type 林鄭我𨳒你老母 is essential for every self-respecting Cantonese speaker. 「屌」你老母 just won’t cut it. Lol.
CAP takes a quite bit of wrestling to get it to install in Windows (in another post) and quite a bit of wrestling to get it to function in Linux. Once you get it working, it’s a very powerful Cantonese IME that allows superfast typing unless you plan to play with words (玩食字). I just can’t praise the IME design enough and I was willing to deal with the quirks which curbs its wide adoption.
Andrew Choi made a few release at his blog page in 2012 (ibus), 2015 (ibus), 2018 (fcitx), 2019 (fcitx4) and 2021 (fcitx4). For the linux version, this blog post is only concerned with the 2021 version (latest at the time of writing).
For Linux CAP, installing the debian package is the easiest part:
sudo dpkg -i fcitx-cap_1.0.0_amd64.deb
The thorns are
- get the CAP show up on the list of valid input methods
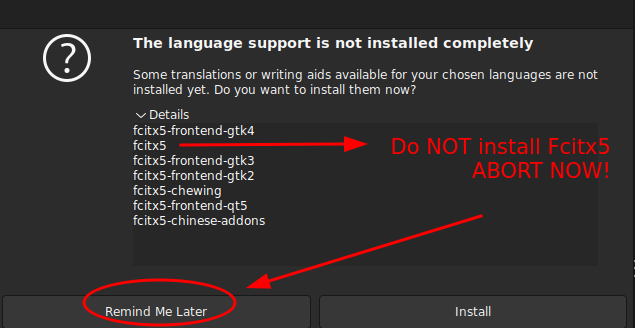
- fend of fcitx5 which is trying to kill CAP
- deal with IME settings state corruption (especially when working with other IME)
- live with being unable to select characters from subsequent pages of selection candidates
CAP is not immediately available as an IME out of the box
(even after installing the .deb package)
.
You will need to add Chinese to “Install / Remove Language” under “Language Support” to get anything to show up there!
Fend off fcitx5
fcitx5 was recently released and Ubuntu is aggressively trying to push it onto every user. However, its very existence kills the currently available CAP which is written for fcitx4 as of the 2021 release. This means you will have to give up fcitx5 if you want to use CAP!
Fcitx5 is considered as a replacement for fcitx4, so whenever Ubuntu sees that you have fcitx installed (which is likely fcitx4), it’ll tempt you into installing fcitx5. DO NOT ACCEPT THE INVITATION! However, fcitx5 do not coexist with fcitx4. Your fcitx4 will be removed the moment you installed fcitx4. To go back to fcitx4, you have first to remove fcitx5 completely then re-install fcitx.
What makes things more complicated is that Ubuntu’s gnome Language Support GUI keeps prompting you to install fcitx5 whenever you start it or do something with it such as installing new languages (which is required as the first non-obvious step). It’ll typically try to deceive you into installing fcitx5 with a dialog box like this:
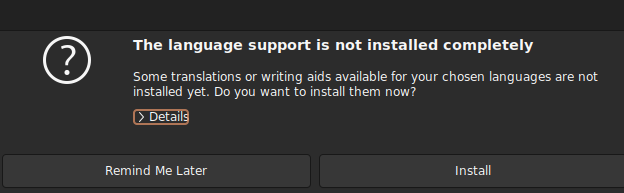
but if you open up the details it’s fcitx5 which will cockblock CAP
However, when you try to perform the first step, if you already have fcitx (fcitx4) installed, adding new languages (required to get CAP) to work will come bundled with upgrades to fcitx5! It’d be super frustrating. So you can choose between the two paths
1) Concede to fcitx5 and downgrade to fcitx4
- install the languages first (with fcitx5 IMEs),
- remove fcitx5
- install fcitx4
2) Prevent fcitx5 in the first place
- remove fcitx4,
- install the languages (no fcitx IMEs)
- install fcitx4
Remove fcitx4
sudo apt purge fcitx
Remove fcitx5
sudo apt purge fcitx5*
Install languages
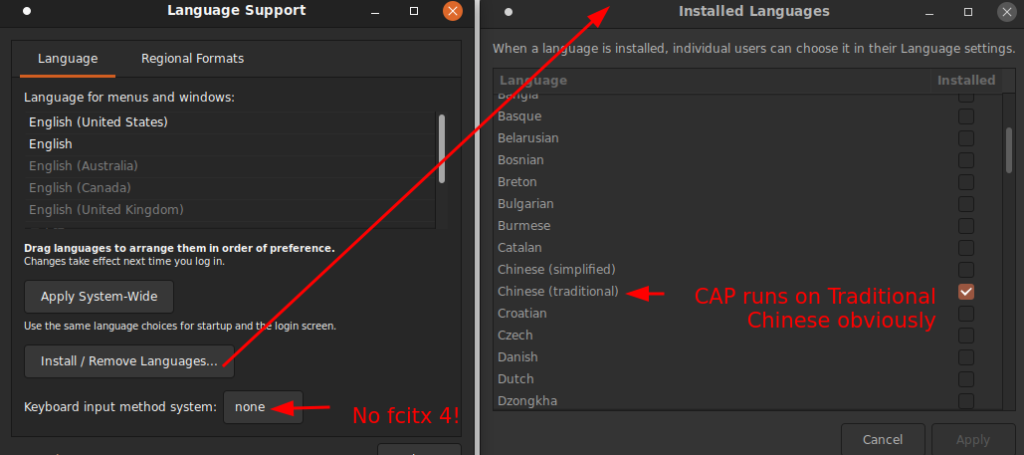
If you already have fcitx installed (path #1), you’ll have to click yes and live with fcitx4 being upgraded to fcitx5 which you’ll have to destroy it later and reinstall fcitx4.
If you already removed fcitx, Language Support will only install IME for other systems such as ibus associated with installed languages
Install fcitx4 AND activate it
sudo apt install fcitx
Remember to select the installed Fcitx 4 as your IME system (not ibus, etc, or none):
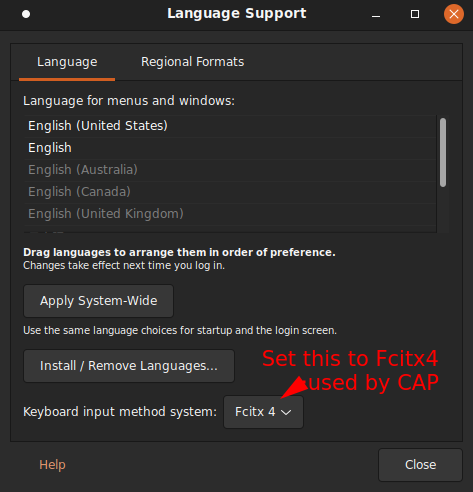
Now CAP is on the list of available IMEs in fcitx-configuration
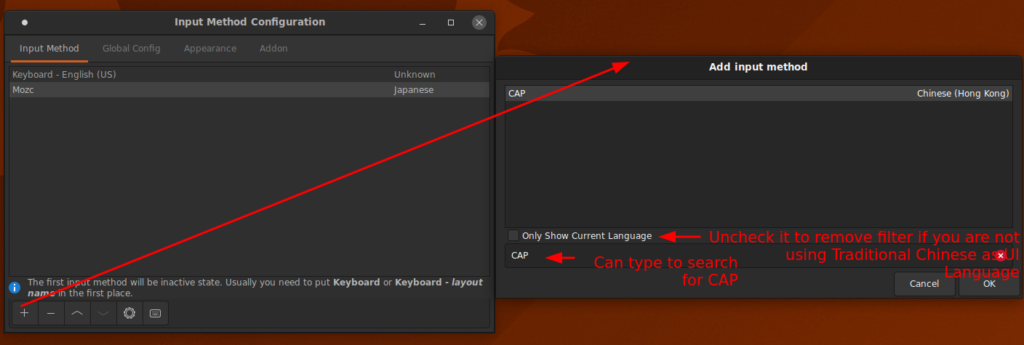
Learn the new shortcut keys that are different from Windows
One default out of the box that’s hard to guess is moving from page to page. It used to be PageUp/PageDown but CAP follows fcitx’s global configuration moving between pages, which is the lower case of +/- keys which is basically =/- because + is upper case while it was intended to be lower case. I know, this is confusing!
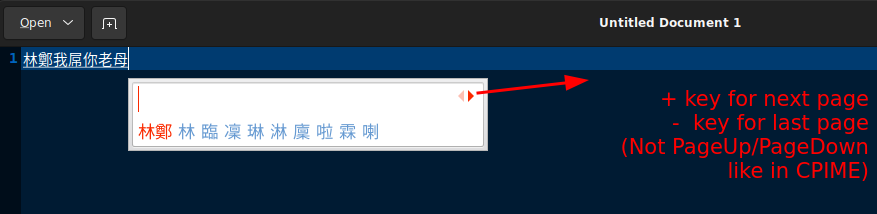
IME switching follows the OLD windows shortcut keys (like Windows 98 and XP days), which
- Ctrl+Space means turning IME on/off (global sense),
- Ctrl+Shift changes IME languages (newer Windows use Alt+Shift by default)
- Shift to temporarily disable/enable the IME (i.e. English mode) but stay within the language state
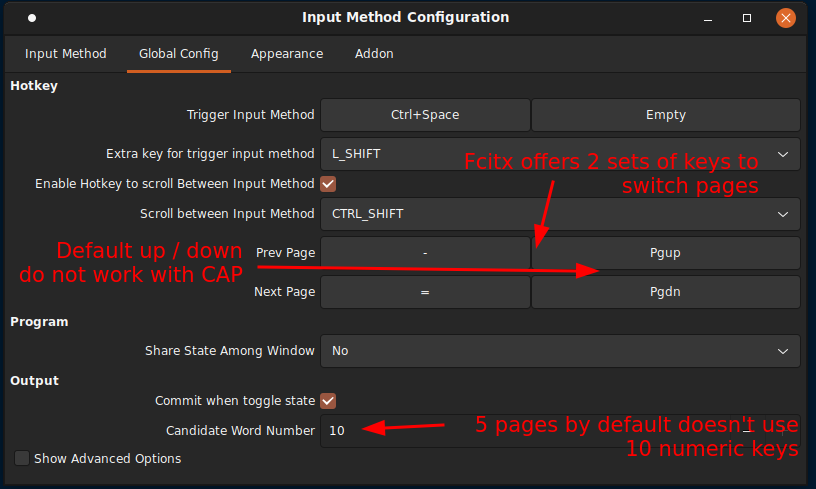
More customizations to get it closer to Windows IME behavior
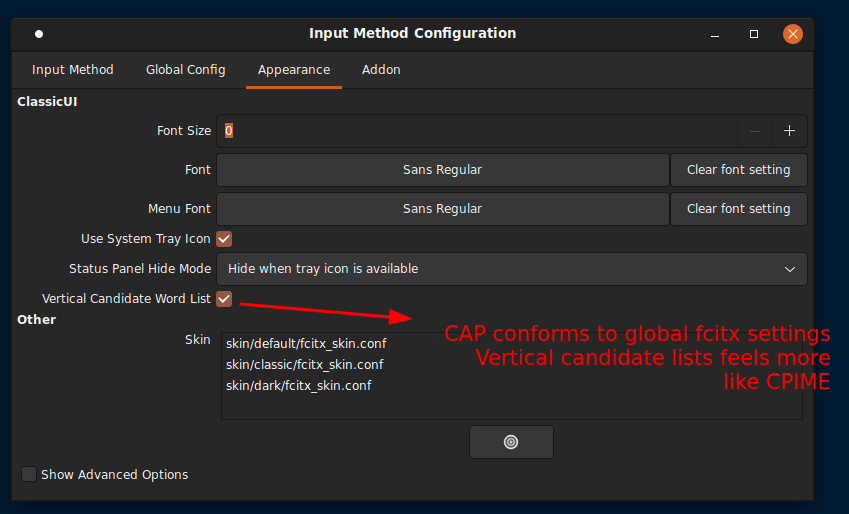
CAP follows the global config settings in fcitx, unlike mozc (Japanese IME) which sometimes play by its own rules which behaves similar to its Windows’ counterpart.
If you are used to CPIME’s vertical lists, you can change it in ‘Appearance’ tab.
CAP candidate selection quirks when used with mozc (bug?)
For some reason, when both CAP and mozc are freshly installed, the first time you use the candidate list in mozc by selecting space/tab, the candidate list will disappear!
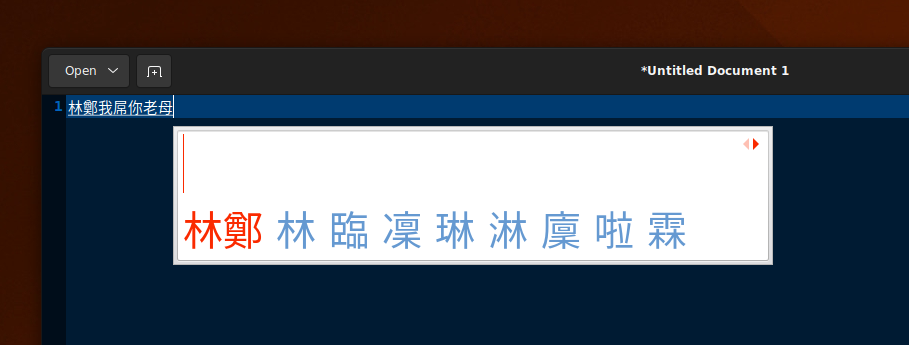
I installed and uninstalled fcitx, mozc and CAP and realized narrowed the bug to this reproducible path. My suspicion is that there’s a setting regarding the candidate selection shortcut (usually by ‘1’~’9’+’0′) parameter state that’s not exposed in fcitx-configuration that was being changed my mozc. And this guess puts me closer as I was able to play around with mozc’s config and found a candidate selection shortcut option
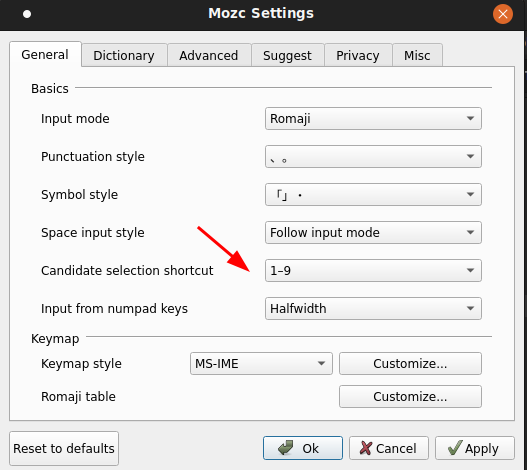
Note that mozc only has a max shortcut of 9 items (instead of 10, that means the ‘0’ key is not available as shortcut key) despite fcitx-configuration’s Global Config has a different idea (which CAP can use the 10th key, aka ‘0’ as candidate selection shortcut)
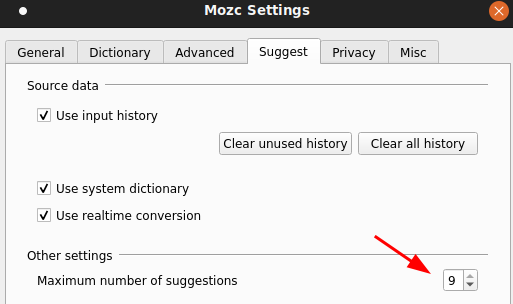
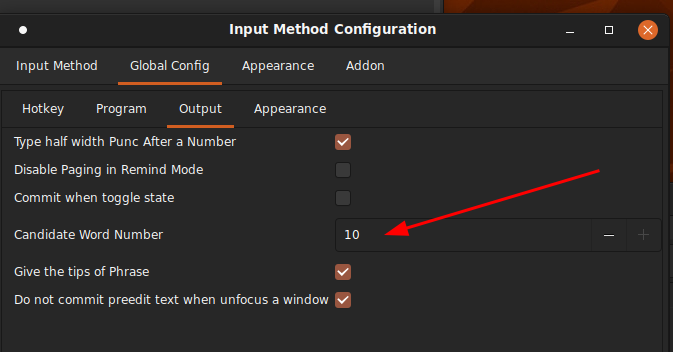
I noticed that after switching ‘1’-‘9’ to ‘a’-‘l’ (or no shortcut) mode, activate it in mozc by using space key to expand selection (this is necessary or the change won’t happen), I get the ‘1’-‘9’+’0’ candidate selection shortcut when I go back to CAP. I also noticed if I messed with the maximum number of suggestions in mozc a few times, I can get into an undefined state in CAP where it shows the candidate selection shortcut for the first few but not the rest, such as this:
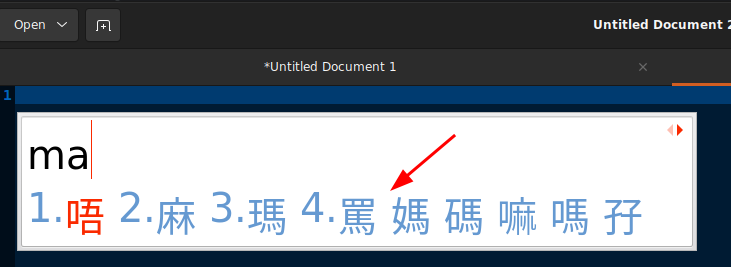
I also noticed CAP has one consistent bug that the candidate selection (not just the keys) ONLY WORKS FOR THE FIRST PAGE! I tried to use the candidate selection shortcuts or click on the character with mouse for subsequent pages, it only commit the current word choice disregarding the selection!
![]()

