I’ve bought many powered USB hubs, even the expensive industrial version like Startech, but they never work reliably when I connect multiple devices that draws quite a bit of power. The behavior is the same (erratic when too many power drawing devices are active within one hub) whether I supply the hub with external power or not.
I suspected the USB hubs wasn’t wired in a way that the USB hub controller understands that I want to have the hub self-powered (powered from an external source like a wall wart instead of drawing the 5V from the USB upstream cable). So I opened up my StarTech and it looked like this:
Love that it’s made in Taiwan and they cut no corners in power management. 10 ports means 3 x 4-port hub chained and they do not share power converters.
On the top left corner, there’s a jumper to set the USB hub to use self-powered instead of bus-powered (default out of the box). I switched the jumpers and the board no longer takes power from the upstream bus and the lights won’t light up until I have the local power connected, which confirms it’s working as a self-powered hub.
Chris Patten, “My main critic when I was the last colonial oppressor (the MPs chuckled) … Percy Cradock, who used to say, …, the leadership in Beijing they may be thuggish dictators he would say, but they are men of their word, now we know that at least one of the things is correct.
The conventional wisdom is that the bad capacitors (the ones with stolen chemical formula) bulged because of the hours you put in it. Today I found that it’s not true. I had a batch of new old stock Trinity S2390 motherboard (used in Agilent logic analyzers) and I noticed all the 100uF 6.3V capacitors bulged and one burst:
Simple Mobile Tools has very nice replacement for basic features no matter you are using the apps that came with your phone’s stock ROM or LineageOS which has the minimum. It’s lightweight yet it does a little more than most default basic apps
Phone
Yet Another Call Blocker (it downloads a database to your phone instead of uploading the phone number to the server to do the check)
Browser
Brave (Can use sync chain that your data is not stored in other people’s cloud)
Youtube Vanced (Youtube app broke which keeps demanding me to update when it’s already the latest) You can change the comments behavior in Vanced settings
Social Media
Twidere: excellent Twitter/Mastodon client (Twitter’s official client is very resource intensive and sluggish.)
I was puzzled by why my dd-wrt router behave erratically each time I change the “Start IP Address” in DHCP leases to an upper range and I just figured out why.
I hate the user interface of dd-wrt with a passion, but it’s the only open source firmware for one of my routers that signed Broadcom’s close source NDA to get its driver SDK so I’m stuck with it:
Ugly as fuck
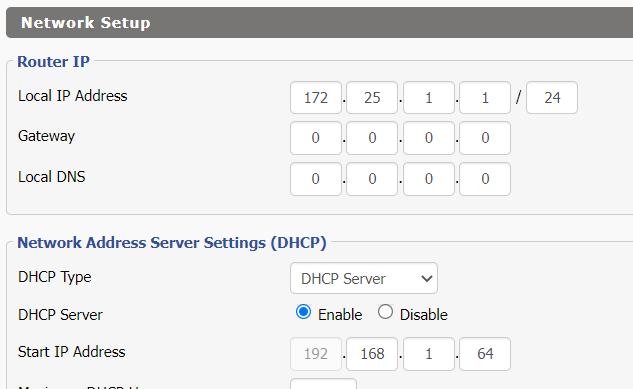
In the bad old days people think it’s a good idea to make 4 little edit boxes for IP addresses than checking if the input conforms to the IP address format with dots. But it cannot detect ‘.’ keypress and jump to the next box (use Tab instead). e.g.
Inconsistent state possible
Start IP address, which is dependent on Local IP Address, is not updated/reflected until you press “Save”. This means every time you make a change, you need to hit “Save” immediately so other dependent settings will make sense before you start editing them.
Features are arranged/grouped like config files
This is bare minimum effort on UI dev, which is not much better than going to linux prompt and edit the config files.
With config files, at least we’d be more careful and try to understand what each key-value pair mean and their relationship map. This lousy web admin UI interface gives a false impression that non-developers knows what they are doing, so it turns into a puzzle that we’ll have to google the answer for every fucking basic application.
Using the web UI instead of editing the config files feels like programming in assembly as an improvement over programming in raw machine code. It’s begrudgingly painful.
One example is the grouping for wireless radio. For most considerate web admin interface, the SSID are grouped logically with your WiFi password, but in dd-wrt, you set SSID in “Basic Settings” and the WiFi password under “Wirelesss Security”. Make sense for the programmer to decouple the radio from the access control (group by features), but it’s not application/use case oriented (group by radio interface), thus it frustrates users.
Non-intuitive (less common) presentation
As described above, out of developer’s convenience, dd-wrt’s web admin UI just do everything that makes beginners’ life miserable or just throw them off. e.g. Windows users are used to specifying the subnet mask in quad-dotted notation like 255.255.255.0, not the CIDR notation like /24:
Confusing names
The names are often too terse that creates confusion with similar named features in a lot of places. e.g. “Wireless GUI Access” does not mean the welcome page for your Guest network, but whether the wireless client have access to the Router Administration‘s Web UI!
It’s probably a few minutes of extra thought to call it “Allow admin web UI: Yes/No”
Another example is AP Isolation, which is under Advanced settings tab for each radio:
Is this isolating APs in a mesh or isolating clients connected to the AP from each other? Turns out it’s the latter! Just say “(For this AP), allow connected wireless clients to talk to each other on the same network: Yes/No”. I think it’s a common use scenario that the regular users should be aware of and shouldn’t be stowed away with obscure radio/PHY-level tweaks (settings aimed for hackers).
Overloaded names
The admin web UI is littered with overloaded names/terms which means something completely different depending on context (like the settings 2 lines above). For example:
Access Point (AP) mode
The SSID here is the SSID of the Access Point (Wifi host. AP station accepting wirelesss clients)
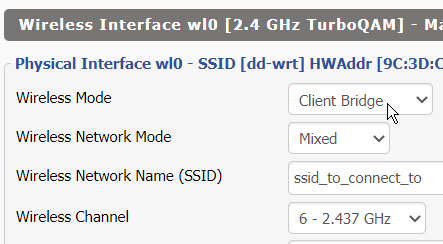
Client/Repeater[Bridge] Mode (all involves the dd-wrt router connecting to certain AP station/SSID)
The SSID here is the SSID where the Client/Repeater-Bridge/Client-Bridge is attempting to connect to that contains the uplink/WAN!
WTF?! The dialog box looks exactly the same despite the wifi section is acting like a completely different device! What the fuck is “Network Configuration: Unbridged” for a Client Bridge?! HELP!
Unchecked invalid combinations that crashes!
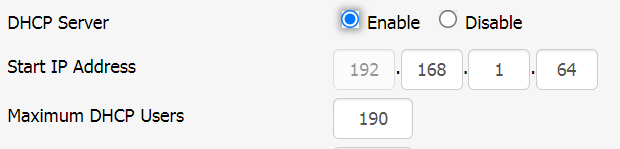
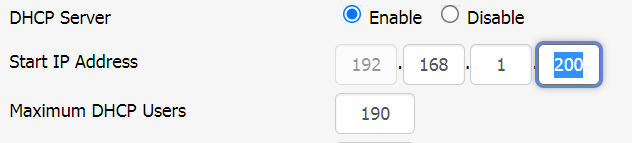
This is the most frustrating behavior and should be considered a bug. I wasted days resetting my router over and over and it keeps hanging randomly after I change the DHCP server’s starting IP address. This is the default out of the box settings:
Default DHCP settings. End IP Address is 192.168.1.253
End IP Address = Start IP Address + Maximum DHCP Users – 1. They probably chose this number to reserve 192.168.1.254 for static IP (like some admin page of other devices). 255 is broadcast IP so of course it shouldn’t be assigned
Moving the the “Start IP Address” up without adjusting “Maximum DHCP Users” accordingly will make your router behave erratically because the DHCP will try to lease IP out of range!
This will corrupt your router’s memory!
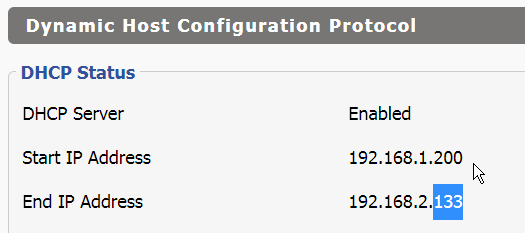
The End IP Address is displayed on Status -> LAN -> Dynamic Host Configuration Protocol -> DHCP Status. And here’s the WTF moment:
The End IP Address is now in a different subnet from the Start IP Address! I’m using /24 so 192.168.1.X is different from 192.168.2.X.
From the web page, the attribute name is “dhcp_num”
This is the code that shows the derived ‘End IP Address” shown above
I don’t know how it is coded, but if this number is computed in a low level way, chances are it’ll write garbage to the memory (for example if the number is used as an array index). I think normally it’d be checked in any not-so-shitty user interface so the invalid state/condition won’t propagate down the code and hang the router. But in my case it did. If I just reboot the router without resetting to the defaults, it’d just hang again after a few interactions (like moving between a few pages or applying a setting).
In any case, this check must be done at user level as even if the low level code say, quietly sets a valid default value when an invalid range was ‘entered’, it’d only surprise the user and make it even harder to troubleshoot. This UI bug is even less excusable as it’s more natural to have users enter the (Start, End) instead of (Start, # of slots). Probably takes half an hour more in coding to layout the UI code to enter ranges (add 4 boxes for quad-dotted notation for End IP and check them instead of just 1 box for # of DHCP leases), but making the user to do mental gymnastics and punish them by if they did it wrong is just outright terrible.
FreshTomato has quite a bit of learning curve, but at least it try to do something that’s sensible for users for common scenarios instead of sticking strictly to how the code/config files are written at developer’s level.
DD-WRT is powerful but the UI suck big time, not because the features overwhelm less tech savvy users, but it’s purely unnecessary torture and pain even you know why it’s done that way. It’s web UI is as helpful as editing the text config file raw.