Technically there’s no static class in C, but a class with all members and functions declared static.
Static classes are like namespaces in many ways. Because no object is constructed (it’s just holding a bunch of variables and functions in the free space), a lot of features and syntax with regular classes do not make sense with static classes.
Because no objects are instantiated
- No constructors or destructors (no objects to make/destroy)
- No operator overloading (you need an instantiation to pass arguments to operator methods)
- No overriding because there are no objects for you to upcast
(nor there’s an object to store the vtable from thevirtualkeyword)!
Static members and methods are treated as free variables scoped by namespaces
- Like C, static members variables live in
.bss(not explicitly initialized ones will be zero-initialized) or.data(initialized) sections, not on stack/heap!
Exception:static const intis internally seen asenum, which the compiler uses it to plug values in the code instead of allocating space for it. - Therefore the syntax is pretty much like free static/global variables
- No constructor to build member variables within the class definition, so they must be defined OUTSIDE the class definition at the top level (just like static/globals), with a SRO (scope resolution operator).
- Static methods acts like (and function overloads the same way as) free functions.
That’s why we often use static methods for helpers.
Namespaces has no access modifiers (public/protected/private/friend), but in return only namespaces can be unnamed/anonymous (which behaves as private)!
Namespaces cannot be inherited, but static classes can!
- Inherited members ARE REFERENCES to the parent!
There’s no extra copies of underlying data if that member is successfully inherited (not shadowed)!
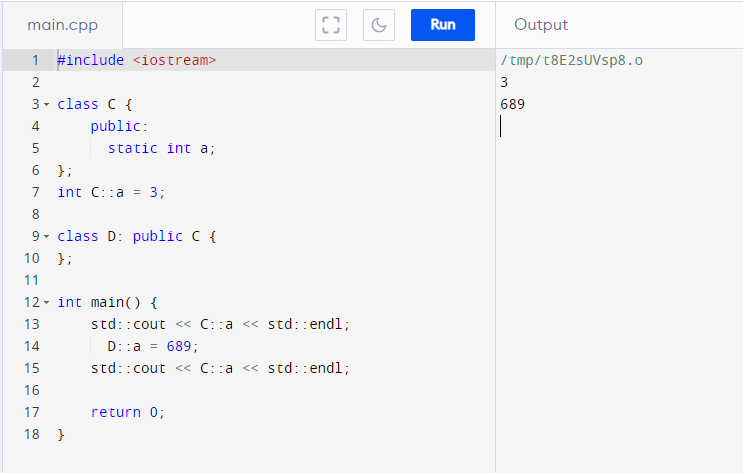
- Members (function or variables) can only be shadowed in the child (never overridden since it’s not an object), which creates a NEW stack variable and hid the reference to the parent member
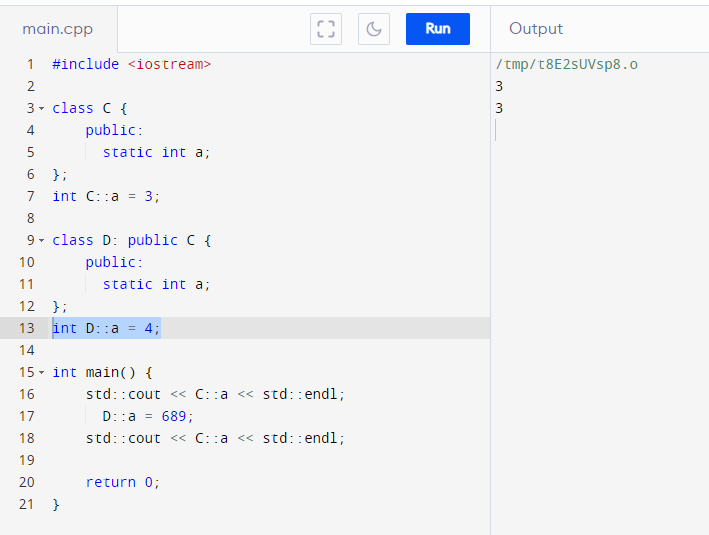
Static class’s inheritance behavior is the same across static classes object-bearing classes! It’s actually more explicit with static members as you’ll need two declarations outside the classes if you shadow.
I am pointing this out to show that inheriting static classes IS NOT cloning namespaces! Static classes behaves as if it’s just ONE CHILD object created on the .bss/.data section (the section for static variables).
This means unlike object-bearing classes, the static class Parent cannot exist on its own if its children are defined!
C++ rules are almost always sensible and coherent; but when combined, sometimes the implications could be surprising on the first sight! When we try to extrapolate expected behaviors in C++, very often we have to think not in terms of the convenient syntax, but the implications of its ground rules (a lot of them stems from C)!
![]()