T && X is equivalent to "if( T) then run X"
T || X is equivalent to "if(!T) then run X"
I don’t exploit this too much in C/C++ because it’s hard to read (and therefore hard to keep track of it to make sure it’s bug free) and most often I’m interested in the output value so I have to watch out for the side effects. However this is common in Bash scripts
Domination Property
In languages that expressions evaluates to a value, sometimes if-statements can be replaced by short-circuit evaluation because short-circuit evaluation exploits the domination property of AND and OR logic operations:
When you FIRST run into the dominant value for the binary operation (0 for AND) and (1 for OR), evaluate no further (i.e. skip the rest) because rest won’t change the overall result away from the dominant value.
So in this use case (emulating if-then statements), what the latter expression X evaluates to or what the combined logic value is irrelevant. We are merely tricking the short-circuit mechanism to trip (short) to NOT evaluate based on what the earlier expression turned out. Action is the ‘norm’. Conditional inaction is the essence of this idiom.
The dual of domination property is idempotent, which is easier to reason because if pre-condition (say T) forces overall expression to boil down to the expression we want to conditionally execute (say X), we are stuck evaluating X if condition T is met.
\newcommand{\Hquad}{\hspace{0.5em}}
\begin{alignat*}{2}
1 \Hquad & \mathrm{AND} & \Hquad X = X \\
0 \Hquad & \mathrm{OR} & \Hquad X = X
\end{alignat*}
These 2 possibilities (domination and idempotency) partitions to space (choices) of possibilities (i.e. cover all possible combinations), in other words there are no other scenarios than described. So the precondition T decides whether you run X or not, which is the equivalent of an if-then statement.
Operator (function) view of logic domination [Functional programming perspective]
By grouping the first value and the binary logic operator with a pair of parenthesis, in dominance view
(0 AND) is also called the ‘clear’ operator
(1 OR) is also called the ‘set’ operator
but this view is not too interesting for our case because we are not interested in what the conditional expression and the overall expression evaluates to, which is signified by ‘clear’ and ‘set’.
On the other hand, (1 AND) and (0 OR) are pass-through (idempotent) operators which passes the evaluation to the latter expression X.
\newcommand{\Hquad}{\hspace{0.5em}}
\begin{alignat*}{2}
(1 \Hquad & \mathrm{AND}) \Hquad & \circ & \Hquad X = X \\
(0 \Hquad & \mathrm{OR}) \Hquad & \circ & \Hquad X = X
\end{alignat*}
Sean Eron Anderson (Stanford CS graphics lab)’s bit twiddling pages often shows a bunch of neat bit tricks, but it’s more like a recipe book than a unified way to summarize the common concepts behind them. Here’s my attempt. This page will get updated as I got the time and more useful insights collected.
Concept: Two ways to get two’s complement
This is the basics of most bit hacks below. Sometimes the definition itself is a bit trick on its own.
You can generalize it to an arbitrary number by subtracting -1 more under the bar on the left hand side and you will get +1 more on the right hand side. Every extra -1 under the bar (bit flips) shows up as +1 outside the bar (bit flips).
This matches the observation that complement schemes (one’s or two’s) both have increasing magnitude move in opposite directions for positive and negative numbers. Look at this table:
Unsigned
Binary
Two’s Complement
7
111
-1
6
110
-2
5
101
-3
4
100
-4
3
011
3
2
010
2
1
001
1
0
000
0
A very important observation that’d be used over and over blow is that in two’s complement, -1 is always a mask of all binary ‘1’s regardless of the word width.
This rule can also read as: magnitude offsets goes in opposite directions
Note that this is NOT distributing bit-flip to two addition/subtraction despite it resembles it with an important distinction that the sign of n changed without turning into (n-1). If it were to distribute, you’ll get (n-2) on the left-hand-side instead of the (n-1) term because the -1 would have been counted twice under distribution.
Bit flips simply doesn’t distribute over the 4 basic (algebraic field) operations. The two’s complement offset is done once and only once when you change the overall representation no matter how many components you break it down into. It’s merely done to shift over the -0 in one’s complement so there’s an extra space for an extra negative number which its positive counterpart is not representable without starting a new digit.
Note to self: the INT_MIN is just the sign bit of ‘1’ followed by all zeros after.
Concept: XOR can be used for bit flips or check for bit changes
Concept: Top bit holds the sign
Sounds simple, but if you keep in mind that (x<0) is really asking to see if the top bit is 1, you can check if two numbers has opposite signs without bit shifting it down by simply XOR-ing them (anything below the top bit are ignored) and use (x^y)<0 to check for the resulting top bit is 1, which signals that the sign bits are different.
Concept: Sign extensions (the top/sign bit gets drag-copied when right shifted)
When you right shift (in signed integers), the top (sign) bit gets drag-copied (sign extended) by the number of bits you right shifted. (Obviously for signed integers, right shifts are zero-filled)
Can exploit this to
drag the top (sign) bit all the way down to the bottom (so you either get all 1s or 0s) to provide a conditional mask based on the sign (see below)
1??????? \gg 7 \textnormal{ (i.e. type bit width - 1)} = 11111111_2 = -1_{10} \\
0??????? \gg 7 \textnormal{ (i.e. type bit width - 1)} = 00000000_2 = +0_{10} \\
Signed extensions also means a negative number will stay negative and a positive number will stay positive if you right shift
Sign extension behavior is not guaranteed by 1987 ANSI C, but it’s standard on pretty much anything more modern than that. Just make sure anything that uses this behavior are inlined (so the implementation can be easily swapped out), well documented/commented, and platform checks/switches are in place, and there’s a way to quickly check with the slower but platform independent implementation.
Concept: Getting a bit mask of a 1s (if true) and all 0s (if false)
The ability to convert a logic evaluation (condition) that gives
is the basis of many branchless ‘drop/keep this if that’ operations.
This can also be achieved by
putting a minus sign in front, such as -(cond) that will convert a (+1, 0) into (-1, 0), or
more efficiently exploiting sign extensions by dragging the top bit to the bottom (by right shifting by the type’s bit length-1)
computing absolute using the two’s complement’s definition of flip all bits and add 1: drag out a mask that shows that sign, which happens to be a do nothing if all 0s and flip all bits if all 1s in an xor, while the mask of all 1s, which is -1, when subtracted, becomes +1 needed to finish the two’s complement (and that’s subtract by 0 for already positive value).
Concept: sets all binary digits below it to a stream of 1s
When you count binary numbers up, you must exhaust all the lower digits by filling them with all 1s before you get to advance to (set) a new digit on the left of them. For example,
This can be exploited to create bit-masks that preserves all digits on the left of the first ‘1’ seen from the right (LSB), ‘0’ at that lowest (LSB) set bit (aka ‘1’), and all ‘1’s below it.
Binary digits are are the (1 or 0) coefficients of a linear combination of powers of 2. Having a loner ‘1’ (aka everything else is 0) means the number is a power of 2.
Being the lone ‘1’ bit in the number means every bit above it must be zero. Any ‘1’s above the right-most ‘1’ means it’s not the loner, hence not a power of 2.
If you subtract 1 from the power-of-2 number, only all bits below (not including) the line ‘1’ bit becomes 1, and that ‘1’ bit position become zero, and as mentioned before, all bits above it are 0s by definition since the ‘1’ we are working on is a loner.
Since the digits in and are mutually exclusive (see example below)
The xor approach does not work because the upper bits are invariant, so we cannot detect the presence of the upper set bits (upper ‘1’s). It unconditionally gives the same bit pattern (mask) marking the lowest first set bit and everything below it 1s and 0s for everything else above it. Which can be exploited to simplify counting the consecutive trailing zeros (from the right) by turning it into counting the contiguous 1s in this invariant pattern, or add 1 to it and binary search the position of the set bit and subtract 1 because the said bit was made into the invariant (xor) pattern as well so +1 move onto the next upper binary digit.
The or approach detects the presence of the upper set bits but it’s a pain to mask out the invariant lower 1s, which curiously you can do by XOR-ing with the invariant pattern generated by or you can do AND-NOT-ing
Which and happens to already does the job by keeping the top bits (which non-zero value detects their presence) yet unconditionally clear the lowest set bit and everything below it.
The gut of is x & (x-1) maneuver is that it clears the bit from the lowest set bit and everything down below
clearLowestSetBitAndEverythingBelow(x): x & (x-1)
This is used by Brian W. Kernighan to count number of set bits by knocking them one off at a time starting from below. Of course the worst case scenario is when the 1s are so dense that the algorithm must go through every bit without jumping past the zeros.
However a special case escaped us, which is x=0. 0x0000 & 0xFFFF is 0, but 0 isn’t a power of 2 unless you consider the minus infinity power which is the territory of floating point anyway. This can be easily patched by making the result unconditionally false if x=0 in the first place.
isPowerOfTwo(x): x && ((x & (x-1))==0)
Note the logical && which means x is first tested for its non-zeroness (by boiling any non-zero value down to +1) and it also enables the efficient short-circuit evaluation which if x is false, which means the result is unconditionally false under &&, the rest are irrelevant so it’s not evaluated.
Concept: Look up table
This is unconditionally the O(1) way because you have a mask of every bit in the type ready and you could index by it. However the penalty is that a load operation could be expensive if not everything can fit in the register file.
breakpoint(): Python’s version of MATLAB’s keyboard() command
callable(): Like MATLAB’s isfunction() but it really checks if there’s a __call__ method
getattr()/hasattr(): MATLAB’s getfield()/isfield(). The 3rd parameter of getfield() is a shortcut to spit out a default if there’s no such field/attribute, which MATLAB doesn’t have
globals()/locals(): more convenient than MATLAB because the whole workspace (current variables) are accessed as a dictionary in Python by calling locals() and globals()
id(): memory address of the item where the variable (reference) is pointing to. Think of it as &x in C.
isinstance(): MATLAB’s isa()
next(): Python favors not actually computing the values until needed so instead it offers a generator (forward iterable) function that spits out one value at each time you kick it with next() and you can’t go back.
chr()/ord(): analogous to MATLAB’s char()/double() cast for characters
Python’s exponentiation is **, not ^ like most other languages (C does not have exponentiation symbol, and ^ was used for xor)
print(…, flush=false) allows a courtesy flush
repr(): MATLAB’s version of disp(), also overloadable standard interface
slice(): MATLAB’s equivalent of colon() special interface
Context Manager
@contextlib.contextmanager decorators basically splits a set-try-yield-finally boilerplate function into 3 parts: __enter__ (everything above yield), BODY (where the yield goes to) and __exit__ (everything below yield), since a with-as statement is a rigidly defined try-finally block, roughly like this:
with EXPR as f:
BODY(using f)
__enter__: f=EVAL(EXPR)
try:
# f isn't evaluated till yield
yield f # Goes to BODY
finally:
__exit__: cleanup(f)
Python uses garbage collectors, so onCleanup() might often work, but it’s not guaranteed to. So any code based on that should not be in production
Answer: Context Manager, a glorified try-catch (more specifically try-finally) block with a rigid structure. It’s a pain in the butt and not fun to deal with if you want to deviate from the native ContextManager that came with the resource opener
‘switch’-case is back as ‘match’-case (the advanced uses are different)
New Python finally supports it, ‘switch’ in C is called ‘match‘ in Python and there are many handy and intuitive syntax just like in MATLAB! Horray!
If you try to do anything fancy with mutables in the cases, be careful about the side effects!
Pass by Variable (Copy-on-Write) like MATLAB
Variables are by large references in Python. Everything including integers are some sort of classes (which are in turn dictionaries with special treatment to certain key names). The garbage collector scans for the last guy using that part of memory not referencing it anymore before cleaning it.
Python even have one ‘None’ for the entire universe with a gazillion things going on pointing to the same memory address where None is stored (that’s why None is idoimatically checked by ‘is’ keyword which checks the address for speed instead of ‘==’ which actually verify the contents for speed). If you look up the reference count (see garbage collector) for commonly used numbers like 1s and 0s, there are thousands of ‘users’ of it!
With C++, it’s a mixture. Complex objects are usually passed by reference for performance reasons but simple structs and data types can be passed as variables (C/C++’s nomenclature calls the non-reference/pointers variables though technically references/pointers are just the same integers identified as addresses) that gets cloned and destroyed when they move across function (stack) boundaries.
In MATLAB, they want it industrial strength, so that’d rather not allow anything insidious/non-transparent to happen in your code by keeping it all pass-by-variable, that is everything is supposed to be treated as different copies as it crosses function boundaries. For performance reason, they figured if you passed a big matrix just for the function to read, MATLAB doesn’t really have to clone that so under the hood you can peak the same matrix that belong to the caller. Once your function changes the contents (they are pretending that it’s a separate copy so of course you can), MATLAB painfully makes a whole copy of it (copy-on-write) which you then have to lug the 2nd (modified) copy around when it travels past function boundaries.
Python takes this idea a lot further by having anything that’s exactly the same (including None or string literals) to point to the same object until you ask to change the contents, then it makes a new copy for you to change and point to the new copy specifically for the variable name you are referencing with.
Answer: The way Python prevents variables passed as parameters passed into a function from getting modified is to separate variables into mutable (lists, dicts, sets), and immutable (tuples, frozendict is a package right now, frozenset, numerics, strings) types. Anything immutable going past the function boundary gets their own local copy.
Classes Boundaries
MATLAB and C++ has stringent access control, but not in Python. There’s not even const correctness. Just signal your intention with variable naming schemes like all caps and __ prefixes.
C++ do not separate helper functions and class (non-instance) methods. What C++ called static members are really just glorified free functions and global variables tucked under the namespace that happened to be in the class (classes started off as namespace for structs then people add features like overloading and dispatch mechanisms). partitioning the global workspace. Whether a scoped helper function call a scoped variable that happened in the same namespace is nothing special to C++
Python does separate these two concepts though. Class method in Python (decorated by @classmethod), on the other hand, are equivalent to C++’s static methods which they are not allowed to touch anything instance-specific, but they can access anything class-specific. Helper functions, which is called ‘Static Method‘ (decorated by @staticmethod) in Python cannot even touch anything specific to the class.
Variable arguments
C++ doesn’t generally do variable arguments because it defeats polymorphism that uses a function signatures (which is a list of your argument types) to figure out which function to dispatch.
MATLAB uses cell to pack variable arguments. The common idioms are varargin{:} and [varargout{1:nargout}]. To accommodate variable arguments, MATLAB have to give up polymorphism but they still have a little bit of it left: they do dispatch based on the first argument type and it’s very useful in avoiding a lot of stupid switching by detecting data types: just use a consistent function name interface and have each data type implement its own method with the same name.
In Python, there’s no such thing as multiple outputs (return variables) on Python: you output a list and it always gets unpacked (just like MATLAB’s deal() function) when you type a list out on left hand side. If the left hand side is a singleton, it will get the full list that’s still packed. If you write out the elements (which makes the left hand side a list), the returned list will have elements assigned to the left hand side depending on your syntax.
This is often a point of agony deciding on output format when I develop MATLAB code. Apparently TMW wondered the same thing too because their own factory code is all over the place on this too. Most of the time it’s not a good idea to have a context-dependent (depending on how many outputs the user supplied) even if you can technically do that by detecting nargout in MATLAB.
Answer: My recommendation is to make sure the simple, most common case got priority, and stuff the juicy side info in packaged data structures (such as array or cells/monads/lists) and stick to a fixed output format whether you are in Python or MATLAB
Late Binding in Lambda / Anonymous Functions: Capture it!
This often throw people off in Python. MATLAB uses early binding, which means when you created that anonymous function (aka lambda), the free variables (parameters that are not running, aka the input arguments to the lambda/anonymous-function) captured the snapshot of the local workspace at the moment the lambda/anonymous-function was created!
Python on the other hand, uses the same approach as C++: late binding. This means you have to explicitly capture (make a snapshot copy) the free variables if you want to associate it with the values when the anonymous function (lambda) was created, not to wait until the lambda was actually called/used to look for what values to use in the free variables.
P = 612
# P was not captured, thus late binding
f = lambda x : print{f'input/running:{x}, param/free:{P}')
# P was captured as p, thus early binding
g = lambda x, p=P: print{f'input/running:{x}, param/free:{p}')
P = 721
f(8964) # shows "input/running: 8964, param/free: 721"
g(8964) # shows "input/running: 8964, param/free: 612"
This article is not for Pythonisms (like ContextManager), etc, the way things should normally be done in Python, but the more non-obvious way to solve problems or new features that are available specifically in Python.
Use / and * argument as separator for different forms of parameter entries!
There is special syntax to separate positional-only, positional/keyword, and keyword-only parameters.
Make a variant of existing class/object
This ninja technique is useful when you want to keep the object mostly the way it is but add/override a few things you think it didn’t do right without inheriting or use composition (hide a copy of object as a member) and write a proxy mirror for every member of it.
In C++, this situation is often used when you want to modify a concrete class that doesn’t have a virtual destructor, most notoriously STL which you are not supposed to inherit from (or else the client might pass a pointer to the parent/base so the child object’s destructors are not called as there are no vtables to keep track of which method to dispatch). In C++, this is often the few use cases that calls for private inheritance.
In Python, because everything is a recursive dict that specially named (magic) functions are recognized, there is a __getattr__ method that gets called whenever a member is accessed, which is the case when the member is called (in Python you simply get the functor as an attribute, aka value in the key-value pairs, in the dictionary and add brackets to call it). This means you can re-route what attributes (members) are returned simply by overloading this method!
If you can overload __getattr__, it also mean you can redefine the member interface of your entire class! So a strategy to make a class have the same exact interface as another class is to hide a copy/reference to the underlying class and re-route the __getattr__ to the underlying object’s __getattr__! Here’s the gist of it:
This can be improved a little bit. Just pick a member name that won’t clash with the underlying object’s attributes/members and simply return the ‘hidden’ object when specifically requested, not self.__obj.__obj.
This is a very powerful luxury that makes Python so lovable if you are not here for industrial strength programming. MATLAB’s classes are hard-wired to your class definition .m file, not something you can update on the fly as you please. Any attempts to do so (aka breaking the safeguards) are Undocumented MATLAB territory where you mess with the Java under the hood and change the metadata property to fool the objects to do what you want.
 which its positive counterpart
which its positive counterpart  is not representable without starting a new digit.
is not representable without starting a new digit. sets all binary digits below it to a stream of 1s
sets all binary digits below it to a stream of 1s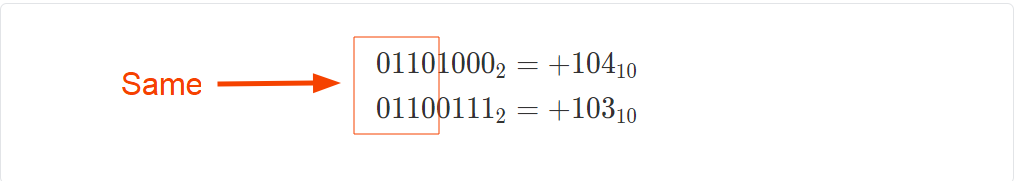
 and
and  or you can do AND-NOT-ing
or you can do AND-NOT-ing