Symantec Ghost has been my favorite tool since high school as the user interface is minimalistic (runs fast) yet intuitive. It pretty much has every single feature (use case) you can imagine organized in a sensible way (unlike the fucking linux man pages that drown you with 4 dozens of command switches not logically organized so you have to skim through the entire thing to find out what is relevant).
The software is well made in general so we can get a lot mileage out of old versions. I recently had to clone a drive over the network yet I don’t want to share the image file. My initial plan is to have the remote computer I plan to image the disk attached to it run as slave (in Master-Slave mode Peer-To_Peer over TCP mode), but there are a few hurdles:
- The documentation didn’t say which port is used. I have to use TCPview to figure it out. It’s Port 6668.
- Turns out slave mode does not support restoring from a image file located from the (puppet-)master. In other words, the when you connect to the slave session, the file dialog box of “From Image” only shows the files on the slave side! WTF!
It’s strange that you can clone a raw drive / partition from master session to slave session, but you cannot choose image file as a source in place of the source drive. I tried the command line before and no avail. After some web searching I realized that I’m not insane. It was the way Ghost is:

The rules inferred from this table means:
- image files ALWAYS stay at the slave session
direct drive/partition copies is always master pushing data to slave.slave drives are never cloned (read)- master cannot read its own files to find image files
- master can only select remote (slave) image files
First of all, direct drive-to-drive copy are bidirectional. The above list is not entirely accurate, so I stroke through the conclusion derived from the incorrect assumptions above. Y:
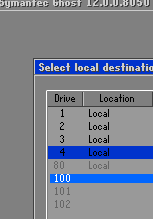
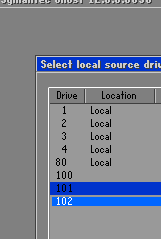
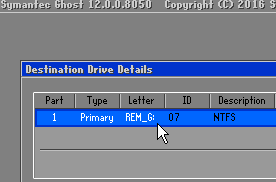
The rules for image files do not make much sense to me. Just can’t come up with a good excuse for it. The session have full access to both storage from both sides, and ghost command line’s logic is to make image files fungible with direct drives/partitions. It doesn’t discourage accidental overwrites or prevent one side’s data from being siphoned. All they did is to tease the user by not allowing them to read files/images from the master computer where the user interaction is.
The first instinct is to restore the GHO image I want to push to the server onto a disk and do the direct clone. This is logically fungible with creating a VHD, mount it, restore the GHO image to the mounted drive, then use direct ‘virtual disk’-to-disk clone to restore the remote (slave) disk. Luckily, newer Ghost has tools to simplify these steps. We’ll need this 3 pieces of clues to figure it out:
- Virtual machine disk image files such as VHD can be used as source or destination
- There’s a command switch to mount virtual machine disk image files internally WITHIN the ghost session (no side effects: windows won’t see it. Won’t persist between ghost sessions)
- GHO files are not directly mountable as a virtual disk even internally within ghost session
So the complicated process can be shorten to converting GHO to VHD and then internally mount the VHD as a direct drive through command switch launching Ghost. Use DEMO.gho as an example:
REM Convert DEMO.gho to DEMO.vhd
ghost -clone,mode=restore,src=DEMO.gho,dst=DEMO.vhd
REM Launch Ghost with DEMO.vhd internally mapped as a (direct) logical drive
ghost -ad=DEMO.vhdI ran into some obscure error messages like “ABORT: 11030, Invalid destination drive” when trying to specify the full absolute path. So instead of fussing with the syntax that breaks the code, I added ghost to my Windows %PATH% environmental variable and run ghost directly at the folder where the files are. I suspect it can be fixed with /translate command switch to make sure the drive letter is not ambigious whether it’s local or remote, but that’s something for later if I have a project that require scripting this reliably.
My cliff notes here.
Run Ghost as slave mode
ghost -tcpsDo this at Ghost master computer
REM Convert DEMO.gho to DEMO.vhd
ghost -clone,mode=restore,src=DEMO.gho,dst=DEMO.vhd
REM Launch Ghost with DEMO.vhd internally mapped as a (direct) logical drive
ghost -ad=DEMO.vhd -tcpm:{IP address of the slave computer}Remember to open port 6668 at the Ghost slave computer.
Appendix
Technically, it’s possible to restore from an image file located AT THE SLAVE side, but it’d be a stupid idea. Initially I thought Ghost would be smart enough to directly use the image file locally on the slave session to clone the drive locally. However, given the speed and my observation with TCPview, this is not the case. It’s doing the stupid thing of crawling the contents of image file from the slave machine in chunks and send it back to the slave!
![]()
